


Wer generative KI (GenAI) heute im Kundenservice einsetzt, sucht meistens nach einem Weg, die Sprachgewalt großer Modelle (LLMs) mit der Faktentreue eigener Daten zu kombinieren. Der Standard-Ansatz hierfür heißt RAG (Retrieval Augmented Generation). Doch wer RAG-Systeme ohne weitere Absicherung in produktiven Kundenprozessen einsetzt, stellt schnell fest: RAG-Systeme lösen ein technisches Teilproblem, ersetzen aber weder Prozesslogik, noch Governance, noch Sicherheitsarchitektur. Genau hier scheitern viele Systeme, sobald sie unter realen Servicebedingungen mit Haftungs- und SLA-Verantwortung eingesetzt werden.
In diesem Beitrag analysieren wir aus technologischer Sicht, warum einfache Baukasten-Lösungen bei komplexen Service-Anforderungen scheitern und wie eine Architektur aussehen muss, die Wissen nicht nur findet, sondern prozessual versteht.
Das Grundproblem von LLMs im Service: Eloquente Antworten sind nicht automatisch Kompetenz
Ein Large Language Model (LLM) ist primär eine statistische Wahrscheinlichkeitsmaschine, aber keine Wissensdatenbank. Es berechnet Wort für Wort, was plausibel klingt. Ohne eine kontrollierte Wissensbasis führt dies unweigerlich zu Halluzinationen. Ein Chatbot verspricht dann Garantiezeiten, neue Produktfeatures oder zeigt veraltete Preise auf. RAG sollte dieses Problem lösen, indem es der KI ein „offenes Buch“ (Ihre Dokumente) zur Verfügung stellt. Doch im Unternehmensumfeld – besonders in der Industrie oder im Handel – reicht das einfache „Nachschlagen“ nicht aus. Wissen ist hier keine bloße Ansammlung von Fakten, sondern besteht aus Logik, Kausalität und Kontext.
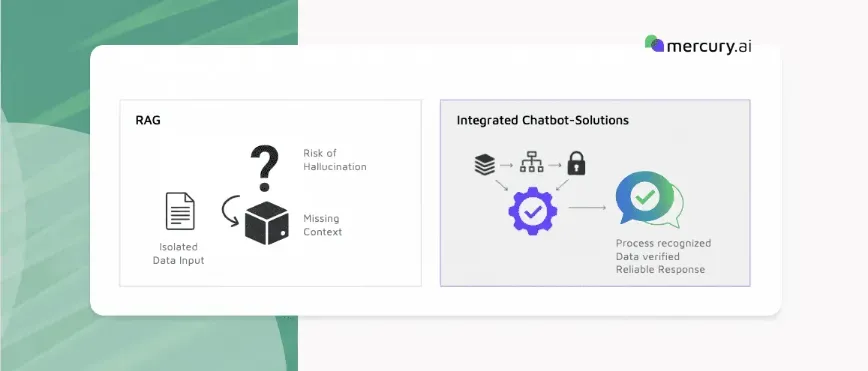
Technische Grenzen von RAG im Kundenservice
Viele Anbieter versprechen „Chatten mit Ihren PDFs“. Das Ergebnis ist meist ein digitaler Zettelkasten, der bei der ersten komplexen Rückfrage versagt. Mercury Intelligence setzt deshalb dort an, wo die meisten Systeme aufhören: bei der Aufbereitung und Bereinigung der Datenbasis.
1. Das Logik-Problem: Kausalketten statt Text-Schnipsel
Service-Wissen ist selten linear. Eine Fehlerdiagnose ist ein komplexer Entscheidungsbaum: „Wenn die LED rot blinkt, prüfen Sie Kabel A. Falls Kabel A intakt ist, tauschen Sie Modul B.“
Der Standard-Fehler: Dokumente werden stumpf in kleine Textblöcke („Chunks“) zerteilt. Dabei wird die Logik oft zerrissen. Die KI findet zwar den Schnipsel „LED blinkt rot“, verliert aber den Bezug zum entscheidenden nächsten Schritt auf der Folgeseite.
Wie Mercury.ai es löst: Wir verarbeiten Dokumente nicht nur als Text, wir extrahieren ihre Struktur. Unser System identifiziert zusammenhängende Kausalketten über Seitengrenzen hinweg. Die KI erhält nicht nur Textbausteine, sondern ein Verständnis für den zugrundeliegenden Prozess. Ein solcher Ansatz ist etwa im Finanzumfeld entscheidend. Bei komplexen Finanzierungsanfragen – etwa im Automotive-Umfeld – reicht es nicht, FAQs zu zitieren. Das System muss valide Entscheidungspfade abbilden, zulässige Produktkombinationen prüfen und regulatorische Rahmenbedingungen berücksichtigen.
Entscheidungen müssen regelbasiert, versioniert und revisionssicher abgebildet werden. Im Finanzumfeld bedeutet das beispielsweise:
Bonitätsabhängige Entscheidungspfade
Produkt- und laufzeitspezifische Konditionsmodelle
Berücksichtigung regulatorischer Vorgaben
Dokumentationspflicht jeder Beratungsempfehlung
Ausschluss nicht zulässiger Produktkombinationen

Die Volkswagen Bank nutzt diesen Ansatz für prozesssichere Finanzierungsberatung per Chat.
Die gesamte Kundengeschichte lesen.
2. RAG-Konsistenzproblem: Warum Datenbasis und Governance entscheidend sind
In gewachsenen Unternehmensstrukturen ist Wissen über Jahre in verschiedenen Systemen entstanden: Ein Handbuch von 2020, eine interne Notiz von 2022 und eine aktuelle Preisliste von 2026. In diesen Quellen existieren oft widersprüchliche Informationen:
Der Standard-Fehler: RAG füttert der KI alles, was semantisch zur Frage passt. Die Folge: Die KI halluziniert eine Antwort aus veralteten und neuen Daten. Für den Kunden entsteht der Eindruck einer sicheren Antwort. Tatsächlich basiert sie auf einer zufälligen Mischung widersprüchlicher Quellen.
Wie Mercury.ai es löst: Ein automatisierter Prüfmechanismus erkennt bereits beim Datenimport Unstimmigkeiten und identifiziert widersprüchliche Informationen. Wir schaffen eine verlässliche Datenbasis, bevor die erste Kundenanfrage gestellt wird. Qualität in der Antwort beginnt bei der Hygiene der Quelle.

3. Warum semantische Suche allein nicht reicht: Hybride Suche und wissenschaftliche Präzision
Als Ausgründung aus der universitären Forschung an der Universität Bielefeld und dem Center for Cognitive Interaction Technology at Bielefeld University (CITEC) wissen wir: Ein Sprachmodell allein ist kein Information-Retrieval-System. Um Enterprise-Anforderungen gerecht zu werden, vereinen wir klassische, mathematisch belegbare Verfahren mit moderner Vektorsuche.
Die Herausforderung im z.B. Maschinenbau liegt nicht in der Menge der Daten, sondern in ihrer Differenzierung. In einer einzigen Kategorie können mehrere tausend Werkzeuge existieren - mit Dutzenden Varianten je Produkt: unterschiedliche Durchmesser, Beschichtungen, Schneidengeometrien, Spannsysteme oder Materialfreigaben. Für einen Servicemitarbeiter bedeutet das: Er muss nicht nur ein Produkt finden, sondern das technisch korrekte Produkt in der richtigen Ausprägung für einen konkreten Anwendungsfall identifizieren.
Schon kleine Abweichungen in der Bezeichnung oder Spezifikation führen zu falschen Empfehlungen. Eine rein semantische Suche erkennt zwar Ähnlichkeiten, kann aber nicht sicherstellen, dass beispielsweise eine fast identisch benannte Schneidplatte mit abweichender Beschichtung oder Geometrie ausgeschlossen wird. In industriellen Umgebungen ist das ein Kosten- und Haftungsrisiko.
Wenn zwei Komponenten fast identisch heißen, aber völlig andere Spezifikationen haben, führt eine rein semantische Suche ins Chaos. Unsere Lösung basiert auf drei Säulen:
Klassisches Retrieval & Keyword-Sicherheit: Während moderne Vektorsuche Bedeutungen versteht, nutzen wir etablierte Verfahren wie z.B. BM25, um bei Fachbegriffen, Seriennummern und spezifischen Codes eine Trefferquote von 100 % zu erreichen.
Wissensgraphen für Kontext-Integrität: Wir bilden Fakten und Abhängigkeiten in Wissensgraphen ab. Sucht ein Nutzer nach Informationen zu einer spezifischen Maschine, stellt der Graph sicher, dass nur Kontext geladen wird, der faktisch mit diesem Objekt verknüpft ist.
Disambiguierung durch Clustering: Wenn Produktnamen oder Fachbegriffe ähnlich klingen, aber unterschiedliche Bedeutungen haben, liefert semantische Suche falsche Ergebnisse. Dies ist ein erhebliches Risiko in der automatisierten Wissensverarbeitung. Durch fortgeschrittene Clustering-Verfahren stellen wir eine scharfe thematische Abgrenzung sicher.
4. Die Sicherheitsarchitektur (Access Control)
Ein Sprachmodell kennt von Natur aus keine Hierarchien oder Vertraulichkeitsstufen. Es verarbeitet die Informationen, die man ihm „füttert", ohne die individuellen Berechtigungen der Fragesteller zu berücksichtigen.
Der Standard-Fehler: Wenn die KI Zugriff auf den gesamten Wissenspool hat, besteht das Risiko der unbefugten Informationsweitergabe. Ein Beispiel für ein konkretes Risiko: Fragt ein Endkunde geschickt nach Rabatten, könnte ein ungesichertes RAG-System interne Händler-Einkaufspreise einfach offenlegen, bloß weil beide Informationen im selben Suchindex liegen.
Ohne Zugriffskontrolle wird ein KI-System schnell zum internen Datenleck, unabhängig davon, wie gut das Sprachmodell ist. Ein Sprachmodell unterscheidet von Haus aus keine Zugriffsrechte.
Wie Mercury.ai es löst: Wir trennen die Suche von der Generierung durch ein striktes, Rechtesystem. Bevor ein Dokumentenfragment den Weg zum Sprachmodell findet, erfolgt eine Echtzeit-Prüfung: Verfügt der Nutzer (z. B. Gast, Mitarbeiter oder Partner) über die notwendige Autorisierung für diese spezifische Quelle? Nur bei expliziter Freigabe wird die Information für die Antwort genutzt.
5. Orchestrierung: Wissen in Wirkung übersetzen
Reines Wissen nützt wenig, wenn daraus kein Handeln folgt. Wenn ein Kunde fragt: „Ich möchte mein Abo kündigen“, hilft ein RAG-System, das die Kündigungsfrist zitiert, nur bedingt weiter.
Mercury Intelligence bedeutet Dialog-Orchestrierung. Unsere Mercury Intelligence identifiziert als zentraler Orchestrator die Intention hinter der Frage:
Handelt es sich um eine Wissensfrage? -> RAG-Antwort auf Basis bereinigter Daten.
Handelt es sich um einen Prozess? -> Übergabe an einen deterministischen Flow, der sicher und DSGVO-konform Daten im CRM ändert.
Wir nutzen generative KI dort, wo Flexibilität und Natürlichkeit gefragt sind. Wir setzen auf strikte Logik dort, wo Prozesse verlässlich sein müssen.
6. Datenschutz und Souveränität: Ihr Wissen bleibt in Ihrer Hand
Für europäische Unternehmen ist die Frage der Datenhoheit keine Randnotiz, sondern eine Existenzfrage. Ein kritischer Punkt bei vielen Standard-Lösungen ist die unklare Verwendung von Unternehmensdaten.
Das Risiko: Bei öffentlichen LLM-Instanzen besteht die Gefahr, dass Eingaben und Dokumenteninhalte zum Training zukünftiger Modellgenerationen verwendet werden. Ihr geschütztes Expertenwissen fließt so unfreiwillig in den globalen Datenpool der Modellbetreiber.
Wie Mercury.ai es löst:
Wir garantieren eine strikte Trennung von Wissen und Modellentwicklung.
Inferenz statt Training: Wir nutzen Ihre Daten ausschließlich als flüchtigen Kontext für die jeweilige Antwortgenerierung. Das zugrundeliegende KI-Modell wird niemals auf echten Benutzerinteraktionen trainiert. Ihr geistiges Eigentum bleibt unangetastet.
Europäisches Hosting: Der gesamte Technologiestack wird auf Servern in Deutschland und Europa betrieben. Damit gewährleisten wir nicht nur volle DSGVO-Konformität, sondern echte digitale Souveränität „Made in Europe“.
Fazit: Von “noch einer KI-Lösung” zur strategischen Infrastruktur
Die Einführung von KI im Kundenservice ist kein einmaliges Projekt, sondern der Aufbau einer strategischen Infrastruktur. Souveränität gewinnen Unternehmen nicht durch den Zugang zu Sprachmodellen, sondern durch die Kontrolle über ihr eigenes Wissen.
Mercury Intelligence kombiniert:
Wissenschaftlich fundierte Retrieval-Verfahren (z.B. BM25, Vektorsuche, ..)
Strukturiertes Wissen durch Wissensgraphen
Enterprise-Grade Sicherheitsarchitektur mit granularer Zugriffskontrolle
DSGVO-konforme Datenverarbeitung in Europa
Das Ergebnis: Ein Chatbot, der nicht nur eloquent antwortet, sondern verlässlich, prozesssicher und rechtskonform arbeitet. Und damit eine messbare Entlastung für Service-Teams schafft.
Nächste Schritte: Erfahren Sie in einem unverbindlichen Gespräch, wie viel Zeit Ihr Service-Team sparen würde, wenn Kundenanfragen automatisch prozesssicher beantwortet werden.


