


Anyone using generative AI (GenAI) in customer service today is usually looking for a way to combine the linguistic power of large language models (LLMs) with the factual accuracy of their own data. The standard approach for this is called RAG (Retrieval Augmented Generation). However, anyone who uses RAG systems in productive customer processes without further safeguards quickly realizes: RAG systems solve a technical sub-problem, but do not replace process logic, governance, or security architecture. This is precisely where many systems fail as soon as they are deployed under real-world service conditions with liability and SLA responsibility.
In this article, we analyze from a technological perspective why simple modular solutions fail when faced with complex service requirements and what an architecture must look like in order to not just find knowledge, but to understand it procedurally.
The Fundamental Problem of LLMs in Service: Eloquent Answers are not Automatically Competence
A Large Language Model (LLM) is primarily a statistical probability engine, not a knowledge database. It calculates word by word what sounds plausible. Without a controlled knowledge base, this inevitably leads to hallucinations. A chatbot then promises warranty periods, new product features, or displays outdated prices. RAG was supposed to solve this problem by providing the AI with an "open book" (your documents). But in the corporate environment – especially in industry or trade – simply "looking things up" is not enough. Here, knowledge is not just a collection of facts, but consists of logic, causality, and context.
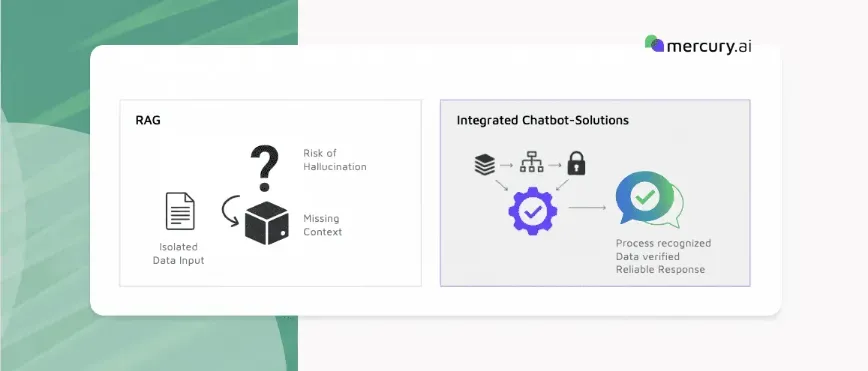
Technical Limits of RAG in Customer Service
Many providers promise "chatting with your PDFs". The result is usually a digital slip box that fails at the first complex follow-up question. Mercury Intelligence therefore starts where most systems stop: at the preparation and cleaning of the data basis.
1. The Logic Problem: Causal Chains instead of Text Snippets
Service knowledge is rarely linear. Troubleshooting is a complex decision tree: "If the LED flashes red, check cable A. If cable A is intact, replace module B."
The Standard Error: Documents are bluntly divided into small text blocks ("chunks"). In the process, the logic is often torn apart. Although the AI finds the snippet "LED flashes red", it loses the connection to the crucial next step on the following page.
How Mercury.ai solves it: We do not just process documents as text; we extract their structure. Our system identifies connected causal chains across page boundaries. The AI receives not just text layout blocks, but an understanding of the underlying process. Such an approach is crucial, for example, in the financial sector. In complex financing inquiries – in the automotive sector, for instance – quoting FAQs is not enough. The system must map valid decision paths, check permitted product combinations, and respect regulatory frameworks.
Decisions must be mapped based on rules, versioned, and audit-proof. In the financial sector, this means, for example:
Credit-rating-dependent decision paths
Product- and term-specific term models
Adhering to regulatory guidelines
Documentation requirements for every advisory recommendation
Exclusion of non-permitted product combinations

Volkswagen Bank uses this approach for process-secure financing advice via chat.
Read the full customer story.
2. RAG Consistency Problem: Why Database and Governance are Crucial
In grown corporate structures, knowledge has been created over years in different systems: a handbook from 2020, an internal memo from 2022, and a current price list from 2026. Conflicting information often exists across these sources:
The Standard Error: RAG feeds the AI everything that matches the question semantically. The result: The AI hallucinates an answer from outdated and new data. This gives the customer the impression of a reliable answer. In reality, it is based on a random mixture of contradictory sources.
How Mercury.ai solves it: An automated validation mechanism detects inconsistencies during the data import and identifies contradictory information. We create a reliable data basis before the first customer query is even made. Quality in the response starts with the cleanliness of the source.

3. Why Semantic Search Alone is not Enough: Hybrid Search and Scientific Precision
As a spin-off from academic research at Bielefeld University and the Center for Cognitive Interaction Technology at Bielefeld University (CITEC), we know: A language model alone is not an information retrieval system. To meet enterprise requirements, we combine classic, mathematically proven methods with modern vector search.
The challenge in areas like mechanical engineering is not the quantity of data, but its differentiation. Within a single category, several thousand tools can exist - with dozens of variants per product: different diameters, coatings, cutting geometries, clamping systems, or material approvals. For a service employee, this means: They do not only have to find a product, but identify the technically correct product in the right configuration for a specific application.
Even minor variations in the designation or specification lead to incorrect recommendations. While a purely semantic search detects similarities, it cannot guarantee that, for example, an almost identically named indexable insert with a different coating or geometry is excluded. In industrial environments, this represents a cost and liability risk.
If two components have almost identical names but completely different specifications, a purely semantic search leads to chaos. Our solution is based on three pillars:
Classic Retrieval & Keyword Security: While modern vector search understands meanings, we use established methods such as BM25 to achieve a 100% keyword match rate for technical terms, serial numbers, and specific codes.
Knowledge Graphs for Context Integrity: We map facts and dependencies in knowledge graphs. If a user searches for information on a specific machine, the graph ensures that only context factually linked to this object is loaded.
Disambiguation through Clustering: When product names or technical terms sound similar but have different meanings, semantic search produces incorrect results. This is a significant risk in automated knowledge processing. Through advanced clustering methods, we ensure sharp thematic differentiation.
4. The Security Architecture (Access Control)
By nature, a language model knows no hierarchies or levels of confidentiality. It processes the information it is "fed" without considering the individual permissions of the person asking.
The Standard Error: If the AI has access to the entire knowledge pool, there is a risk of unauthorized information disclosure. An example of a concrete risk: If an end customer cleverly asks about discounts, an unsecured RAG system could simply disclose internal dealer purchase prices, just because both pieces of information reside in the same search index.
Without access control, an AI system quickly becomes an internal data leak, regardless of how good the language model is. A language model does not distinguish access rights by default.
How Mercury.ai solves it: We separate search from generation through a strict permissions system. Before a document fragment finds its way to the language model, a real-time check takes place: Does the user (e.g., guest, employee, or partner) have the necessary authorization for this specific source? The information is only used for the response if there is explicit approval.
5. Orchestration: Translating Knowledge into Action
Pure knowledge is of little use if no action follows from it. If a customer asks: "I want to cancel my subscription", a RAG system that simply quotes the cancellation period is of limited help.
Mercury Intelligence means dialogue orchestration. Our Mercury Intelligence, acting as the central orchestrator, identifies the intention behind the question:
Is it a knowledge question? -> RAG response based on cleaned data.
Is it a process? -> Handover to a deterministic flow that securely modifies data in the CRM in compliance with GDPR.
We use generative AI where flexibility and naturalness are needed. We rely on strict logic where processes must be reliable.
6. Data Protection and Sovereignty: Your Knowledge Remains in Your Hands
For European companies, the question of data sovereignty is not a minor detail, but an existential issue. A critical point with many standard solutions is the unclear use of corporate data.
The Risk: With public LLM instances, there is a danger that inputs and document contents are used to train future model generations. Your protected expert knowledge is thus involuntarily fed into the global data pool of the model operators.
How Mercury.ai solves it:
We guarantee a strict separation of knowledge and model development.
Inference instead of Training: We use your data exclusively as transient context for the respective response generation. The underlying AI model is never trained on real user interactions. Your intellectual property remains untouched.
European Hosting: The entire technology stack is operated on servers in Germany and Europe. This ensures not only full GDPR compliance, but true digital sovereignty "Made in Europe".
Conclusion: From "Just Another AI Solution" to Strategic Infrastructure
Implementing AI in customer service is not a one-off project, but the building of a strategic infrastructure. Companies gain sovereignty not through access to language models, but through control over their own knowledge.
Mercury Intelligence combines:
Scientifically proven retrieval methods (e.g. BM25, vector search, etc.)
Structured knowledge via knowledge graphs
Enterprise-grade security architecture with granular access control
GDPR-compliant data processing in Europe
The result: A chatbot that doesn't just reply eloquently, but works reliably, process-securely, and in compliance with the law. And thereby achieves measurable relief for service teams.
Next steps: Learn in a non-binding conversation how much time your service team would save if customer queries were answered automatically and with process security.


